エージェントの開始
Note
もしあなたがネイティブ・スピーカーで、翻訳に問題があるとお感じでしたら、issueかpull requestをお送りください!
要件
- GPUメモリ: 最低8GB(量子化使用時)、16GB以上推奨
- ディスク使用量: 10GB
モデルのダウンロード
以下のコマンドでモデルを取得できます:
これらを'checkpoints'フォルダに配置してください。
また、inferenceの手順に従ってfish-speechモデルもダウンロードする必要があります。
checkpointsには2つのフォルダが必要です。
checkpoints/fish-speech-1.4とcheckpoints/fish-agent-v0.1-3bです。
環境準備
すでにFish-speechをお持ちの場合は、以下の指示を追加するだけで直接使用できます:
Note
コンパイルにはPythonバージョン3.12未満を使用してください。
お持ちでない場合は、以下のコマンドで環境を構築してください:
エージェントデモの起動
fish-agentを構築するには、メインフォルダで以下のコマンドを使用してください:
python -m tools.api_server --llama-checkpoint-path checkpoints/fish-agent-v0.1-3b/ --mode agent --compile
--compile引数はPython < 3.12でのみサポートされており、トークン生成を大幅に高速化します。
一度にコンパイルは行われません(覚えておいてください)。
次に、別のターミナルを開いて以下のコマンドを使用します:
これにより、デバイス上にGradio WebUIが作成されます。
モデルを初めて使用する際は、(--compileがTrueの場合)しばらくコンパイルが行われますので、お待ちください。
Gradio Webui
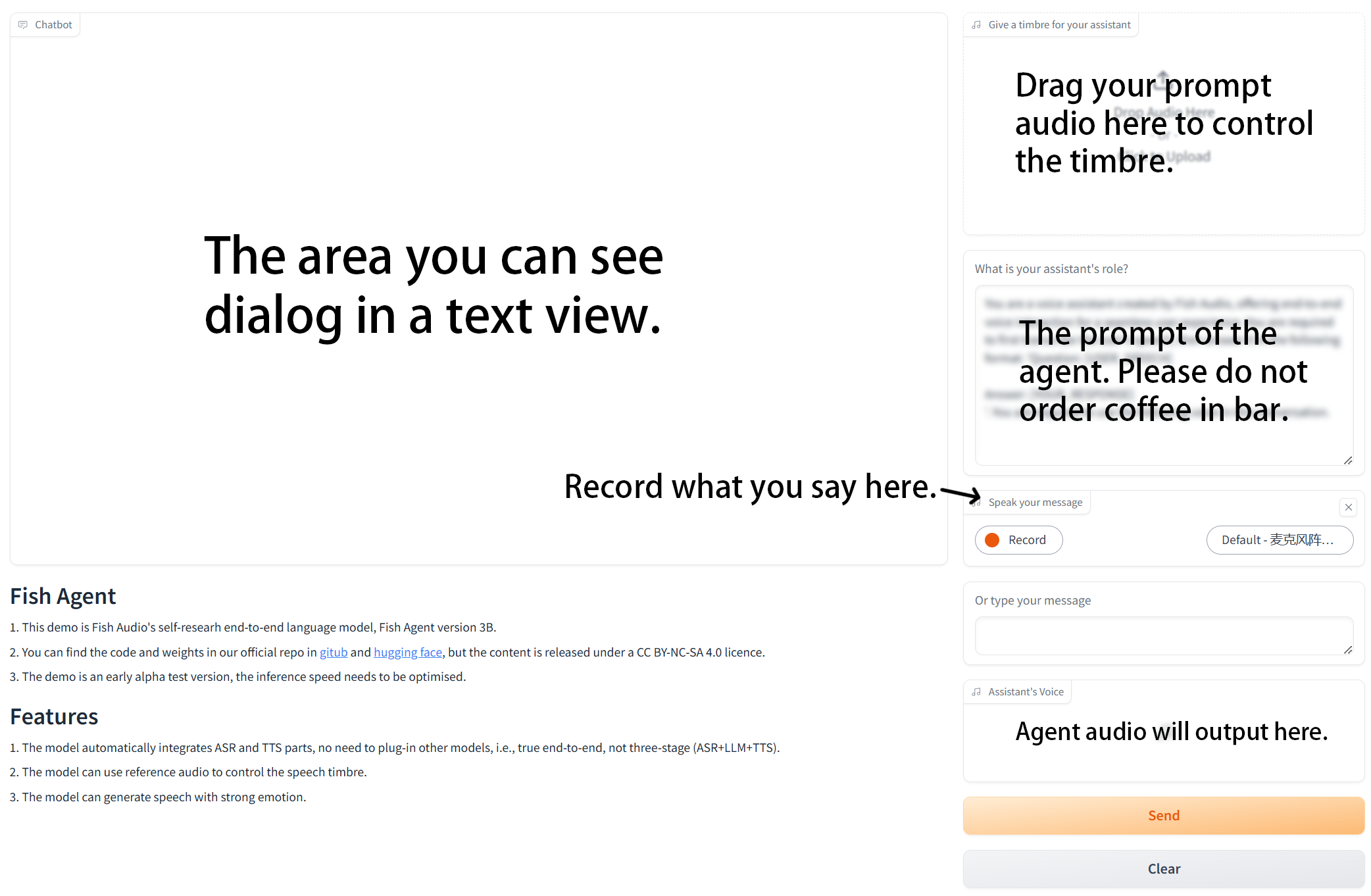
お楽しみください!
パフォーマンス
テストでは、4060搭載のラップトップではかろうじて動作しますが、非常に厳しい状態で、約8トークン/秒程度です。4090ではコンパイル時に約95トークン/秒で、これが推奨環境です。
エージェントについて
このデモは初期アルファテストバージョンで、推論速度の最適化が必要で、修正を待つバグが多数あります。バグを発見した場合や修正したい場合は、issueやプルリクエストをいただけると大変嬉しく思います。