

Aviso de Licença
Este repositório e todos os pesos de modelo associados são lançados sob a FISH AUDIO RESEARCH LICENSE. Consulte LICENSE para mais detalhes.
Isenção de Responsabilidade Legal
Não nos responsabilizamos por qualquer uso ilegal da base de códigos. Consulte as regulamentações locais sobre DMCA e outras leis relacionadas.
Início Rápido
Comece pela documentação
Esta é a documentação oficial do Fish Audio S2. Você pode começar por aqui:
- Instalação
- Inferência por Linha de Comando
- Inferência WebUI
- Inferência via Servidor
- Configuração Docker
[!IMPORTANT] Para servidor com SGLang, consulte o SGLang-Omni README.
Guia para agentes LLM
Instale e configure o Fish Audio S2 seguindo as instruções em https://speech.fish.audio/pt/install/ .
Fish Audio S2
O melhor sistema de conversão de texto em fala entre código aberto e código fechado
O Fish Audio S2 é o modelo mais recente da Fish Audio. Treinado com mais de 10 milhões de horas de áudio em cerca de 50 idiomas, o S2 combina alinhamento por reforço com uma arquitetura Dual-Autoregressive para gerar fala natural, realista e emocionalmente expressiva.
O S2 permite controle fino de prosódia e emoção dentro da própria frase com tags em linguagem natural, como [laugh], [whispers] e [super happy], além de oferecer suporte nativo a múltiplos falantes e múltiplos turnos.
AcesVisite o site da Fish Audio para demonstrações ao vivo. Leia a postagem no blog e o relatório técnico para mais detalhes.
Variantes do Modelo
| Modelo | Tamanho | Disponibilidade | Descrição |
|---|---|---|---|
| S2-Pro | 4B parâmetros | HuggingFace | Modelo carro-chefe completo com máxima qualidade e estabilidade |
Mais detalhes podem ser encontrados no relatório técnico.
Resultados de Benchmark
| Benchmark | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (Chinês) | 0.54% (melhor geral) |
| Seed-TTS Eval — WER (Inglês) | 0.99% (melhor geral) |
| Audio Turing Test (com instrução) | 0.515 média a posteriori |
| EmergentTTS-Eval — Taxa de vitória | 81.88% (maior geral) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — Qualidade | 4.51 / 5.0 |
| Multilíngue (MiniMax Testset) — Melhor WER | 11 de 24 idiomas |
| Multilíngue (MiniMax Testset) — Melhor SIM | 17 de 24 idiomas |
No Seed-TTS Eval, o S2 obteve o menor WER entre todos os modelos avaliados, incluindo sistemas fechados: Qwen3-TTS (0.77/1.24), MiniMax Speech-02 (0.99/1.90) e Seed-TTS (1.12/2.25). No Audio Turing Test, o valor 0.515 supera o Seed-TTS (0.417) em 24% e o MiniMax-Speech (0.387) em 33%. No EmergentTTS-Eval, o S2 se destacou especialmente em paralinguística (91.61%), perguntas (84.41%) e complexidade sintática (83.39%).
Destaques
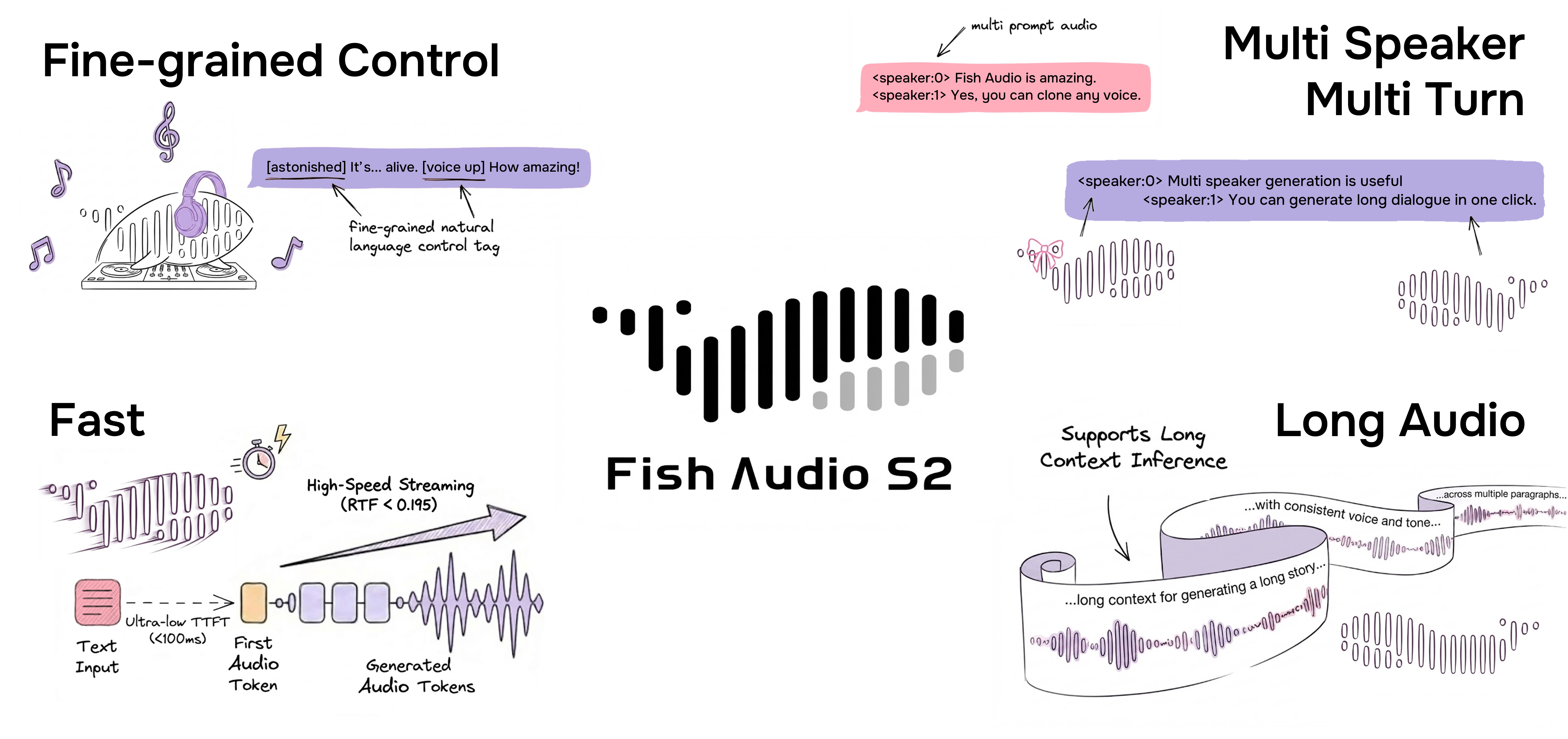
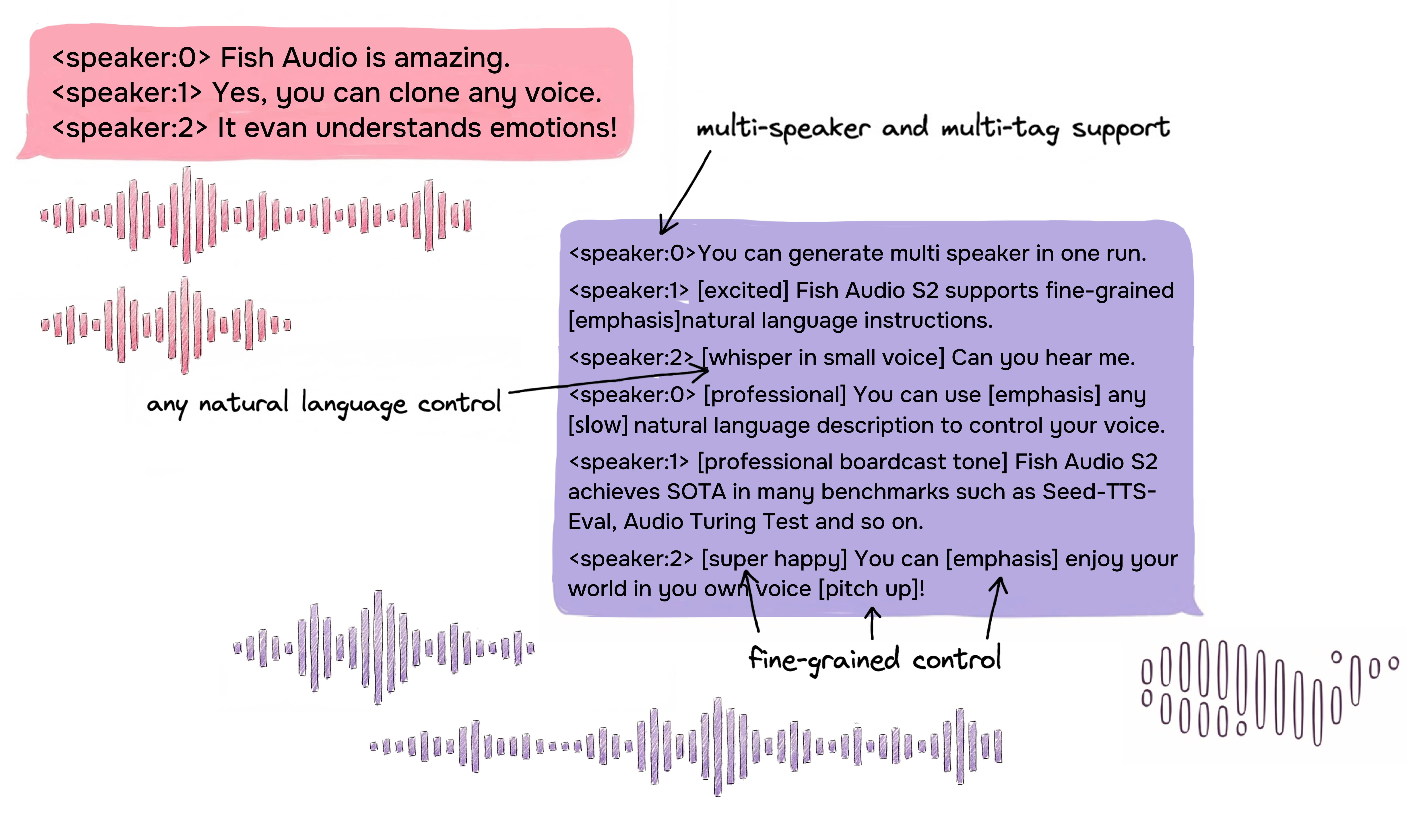
Controle Inline Refinado via Linguagem Natural
O Fish Audio S2 permite controle localizado da geração de fala ao incorporar instruções em linguagem natural diretamente em posições específicas de palavras ou frases no texto. Em vez de depender de um conjunto fixo de tags predefinidas, o S2 aceita descrições textuais livres, como [whisper in small voice], [professional broadcast tone] ou [pitch up], permitindo controle de expressão aberto no nível da palavra.
Arquitetura Dual-Autoregressive
O S2 é baseado em um transformer apenas decodificador, combinado com um codec de áudio RVQ (10 codebooks, ~21 Hz de taxa de quadros). A arquitetura Dual-AR divide a geração em duas etapas:
- Slow AR opera no eixo temporal e prevê o codebook semântico principal.
- Fast AR gera os 9 codebooks residuais restantes em cada passo de tempo, reconstruindo detalhes acústicos finos.
Esse desenho assimétrico (4B parâmetros no eixo temporal e 400M no eixo de profundidade) mantém a inferência eficiente sem sacrificar fidelidade de áudio.
Alinhamento por Reforço
O S2 usa Group Relative Policy Optimization (GRPO) no pós-treinamento. Os mesmos modelos usados para filtrar e anotar dados de treino são reutilizados diretamente como modelos de recompensa no RL, eliminando o desalinhamento de distribuição entre os dados de pré-treinamento e os objetivos de pós-treinamento. O sinal de recompensa combina precisão semântica, aderência à instrução, preferência acústica e similaridade de timbre.
Streaming em Produção com SGLang
Como a arquitetura Dual-AR é estruturalmente isomórfica a LLMs autoregressivos padrão, o S2 herda diretamente as otimizações nativas de serving do SGLang, incluindo continuous batching, paged KV cache, CUDA graph replay e prefix caching com RadixAttention.
Em uma única NVIDIA H200:
- RTF (Real-Time Factor): 0.195
- Tempo até o primeiro áudio: ~100 ms
- Throughput: mais de 3.000 acoustic tokens/s mantendo RTF abaixo de 0.5
Suporte Multilíngue
O Fish Audio S2 oferece suporte a conversão de texto em fala multilíngue de alta qualidade sem a necessidade de fonemas ou processamento específico de idioma. Incluindo:
Inglês, Chinês, Japonês, Coreano, Árabe, Alemão, Francês...
E MUITO MAIS!
A lista está em constante expansão, verifique o Fish Audio para os lançamentos mais recentes.
Geração Nativa de Múltiplos Falantes
O Fish Audio S2 permite enviar um áudio de referência com vários falantes; o modelo processa as características de cada voz por meio do token <|speaker:i|>. Depois, você controla o comportamento do modelo com o token de ID do falante, permitindo incluir várias vozes em uma única geração. Assim, não é mais necessário subir um áudio de referência separado para cada falante.
Geração de Múltiplos Turnos
Graças à extensão do contexto do modelo, nosso modelo agora pode usar informações anteriores para melhorar a expressividade e a naturalidade dos conteúdos gerados subsequentemente.
Clonagem de Voz Rápida
O Fish Audio S2 suporta clonagem de voz precisa usando uma pequena amostra de referência (tipicamente de 10 a 30 segundos). O modelo captura o timbre, o estilo de fala e as tendências emocionais, produzindo vozes clonadas realistas e consistentes sem ajuste fino adicional. Para usar o servidor SGLang, consulte SGLang-Omni README .
Créditos
Relatório Técnico
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
@misc{liao2026fishaudios2technical,
title={Fish Audio S2 Technical Report},
author={Shijia Liao and Yuxuan Wang and Songting Liu and Yifan Cheng and Ruoyi Zhang and Tianyu Li and Shidong Li and Yisheng Zheng and Xingwei Liu and Qingzheng Wang and Zhizhuo Zhou and Jiahua Liu and Xin Chen and Dawei Han},
year={2026},
eprint={2603.08823},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.08823},
}