

라이선스 공지
이 코드베이스 및 관련 모델 가중치는 FISH AUDIO RESEARCH LICENSE 하에 릴리스되었습니다. 자세한 내용은 LICENSE를 참조하십시오.
법적 면책 조항
코드베이스의 불법적인 사용에 대해 당사는 어떠한 책임도 지지 않습니다. DMCA 및 기타 관련 법률에 관한 현지 규정을 참조하십시오.
빠른 시작
문서로 바로 시작하기
Fish Audio S2 공식 문서입니다. 아래 링크에서 바로 시작할 수 있습니다.
[!IMPORTANT] SGLang 서버는 SGLang-Omni README를 참고하세요.
LLM Agent 가이드
Fish Audio S2
오픈 소스와 클로즈드 소스 모두에서 가장 뛰어난 텍스트 음성 변환 시스템
Fish Audio S2는 Fish Audio가 개발한 최신 모델입니다. 약 50개 언어, 1,000만 시간 이상의 오디오 데이터로 학습되었고, 강화학습 정렬과 Dual-Autoregressive 아키텍처를 결합해 자연스럽고 사실적이며 감정 표현이 풍부한 음성을 생성합니다.
S2는 [laugh], [whispers], [super happy] 같은 자연어 태그를 사용해 운율과 감정을 문장 내부에서 세밀하게 제어할 수 있으며, 멀티 화자/멀티 턴 생성도 네이티브로 지원합니다.
실시간 데모는 Fish Audio 웹사이트에서, 자세한 내용은 블로그 글에서 확인할 수 있습니다.
모델 변형
| 모델 | 크기 | 가용성 | 설명 |
|---|---|---|---|
| S2-Pro | 4B 매개변수 | HuggingFace | 최고 수준의 품질과 안정성을 제공하는 풀기능 플래그십 모델 |
모델 상세는 기술 보고서를 참고하세요.
벤치마크 결과
| 벤치마크 | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (중국어) | 0.54% (전체 최고) |
| Seed-TTS Eval — WER (영어) | 0.99% (전체 최고) |
| Audio Turing Test (지시 포함) | 0.515 사후 평균 |
| EmergentTTS-Eval — 승률 | 81.88% (전체 최고) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — 품질 | 4.51 / 5.0 |
| 다국어 (MiniMax Testset) — 최고 WER | 24개 언어 중 11개 |
| 다국어 (MiniMax Testset) — 최고 SIM | 24개 언어 중 17개 |
Seed-TTS Eval에서 S2는 클로즈드 소스 시스템을 포함한 전체 비교 모델 중 가장 낮은 WER를 기록했습니다: Qwen3-TTS (0.77/1.24), MiniMax Speech-02 (0.99/1.90), Seed-TTS (1.12/2.25). Audio Turing Test에서는 0.515를 기록해 Seed-TTS (0.417) 대비 24%, MiniMax-Speech (0.387) 대비 33% 높았습니다. EmergentTTS-Eval에서는 파라언어 표현(91.61%), 의문문(84.41%), 구문 복잡도(83.39%)에서 특히 강한 성능을 보였습니다.
주요 특징
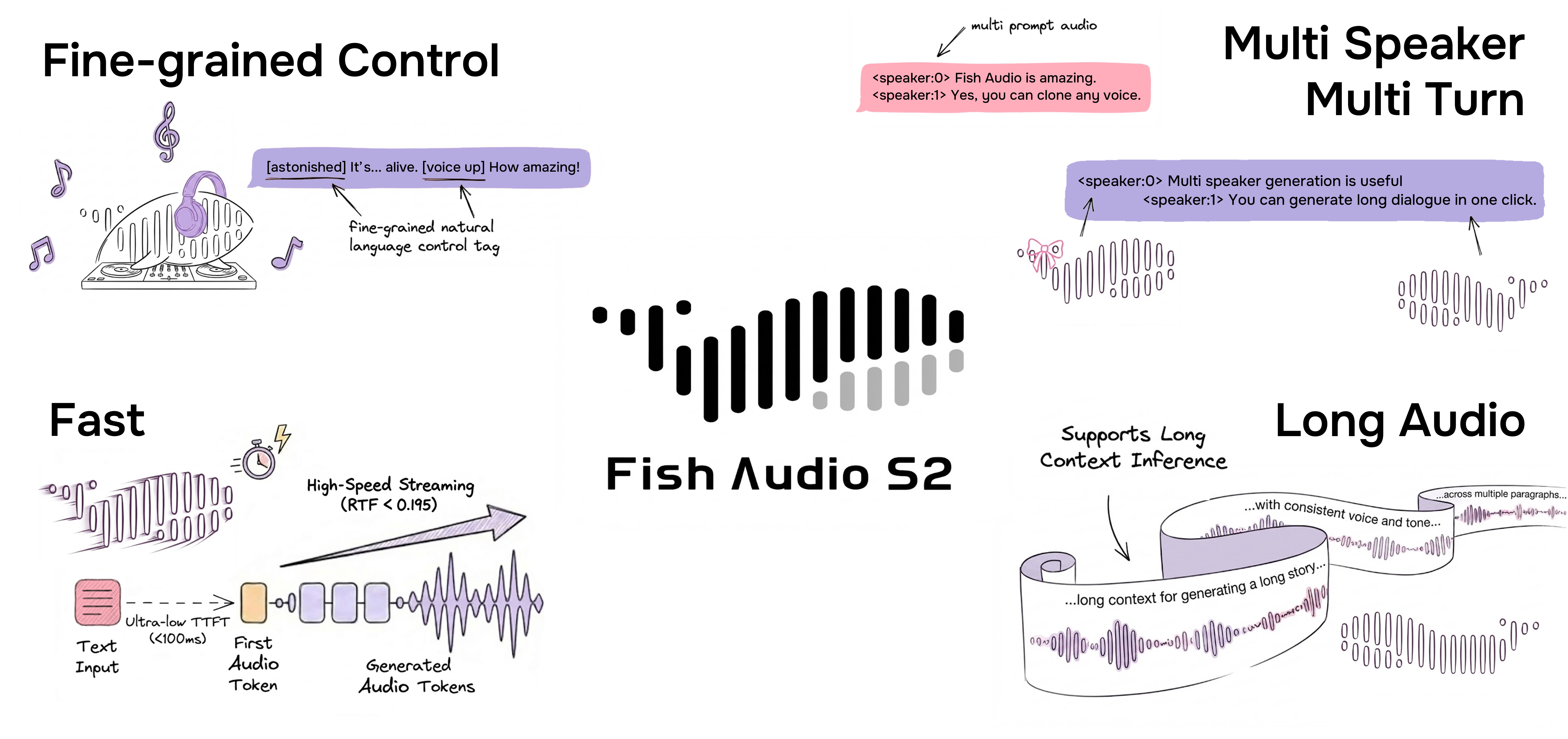
자연어 기반 세밀한 인라인 제어
Fish Audio S2는 텍스트의 특정 단어 또는 구문 위치에 자연어 지시를 직접 삽입해 음성 생성을 국소적으로 제어할 수 있습니다. 고정된 사전 정의 태그에 의존하는 대신, S2는 [whisper in small voice], [professional broadcast tone], [pitch up] 같은 자유 형식 텍스트 설명을 받아 단어 수준의 개방형 표현 제어를 지원합니다.
Dual-Autoregressive 아키텍처
S2는 decoder-only Transformer와 RVQ 기반 오디오 코덱(10 codebooks, 약 21 Hz 프레임레이트)을 결합합니다. Dual-AR은 생성 과정을 두 단계로 나눕니다.
- Slow AR: 시간축을 따라 동작하며 주 semantic codebook을 예측
- Fast AR: 각 시점에서 나머지 9개 residual codebook을 생성해 세밀한 음향 디테일을 복원
이 비대칭 설계(시간축 4B 파라미터, 깊이축 400M 파라미터)는 음질을 유지하면서 추론 효율을 높입니다.
강화학습 정렬
S2는 후학습 정렬을 위해 Group Relative Policy Optimization(GRPO)을 사용합니다. 학습 데이터 필터링/라벨링에 쓰인 동일한 모델을 RL 보상 모델로 재사용해, 사전학습 데이터 분포와 후학습 목표 간의 분포 불일치를 줄였습니다. 보상 신호는 의미 정확도, 지시 준수도, 음향 선호 점수, 음색 유사도를 함께 반영합니다.
SGLang 기반 프로덕션 스트리밍
Dual-AR 구조는 표준 자기회귀 LLM과 구조적으로 동형이기 때문에, S2는 SGLang의 LLM 서빙 최적화를 그대로 활용합니다. 예: continuous batching, paged KV cache, CUDA graph replay, RadixAttention 기반 prefix caching.
NVIDIA H200 단일 GPU 기준:
- 실시간 계수(RTF): 0.195
- 첫 오디오 출력까지 시간: 약 100 ms
- 처리량: RTF 0.5 미만 유지 시 3,000+ acoustic tokens/s
다국어 지원
Fish Audio S2는 음소나 언어별 전처리 없이 고품질 다국어 텍스트 음성 변환을 지원합니다. 포함 사항:
영어, 중국어, 일본어, 한국어, 아랍어, 독일어, 프랑스어...
그리고 더 많이!
목록은 계속 확장되고 있습니다. 최신 릴리스는 Fish Audio를 확인하세요.
네이티브 멀티 화자 생성
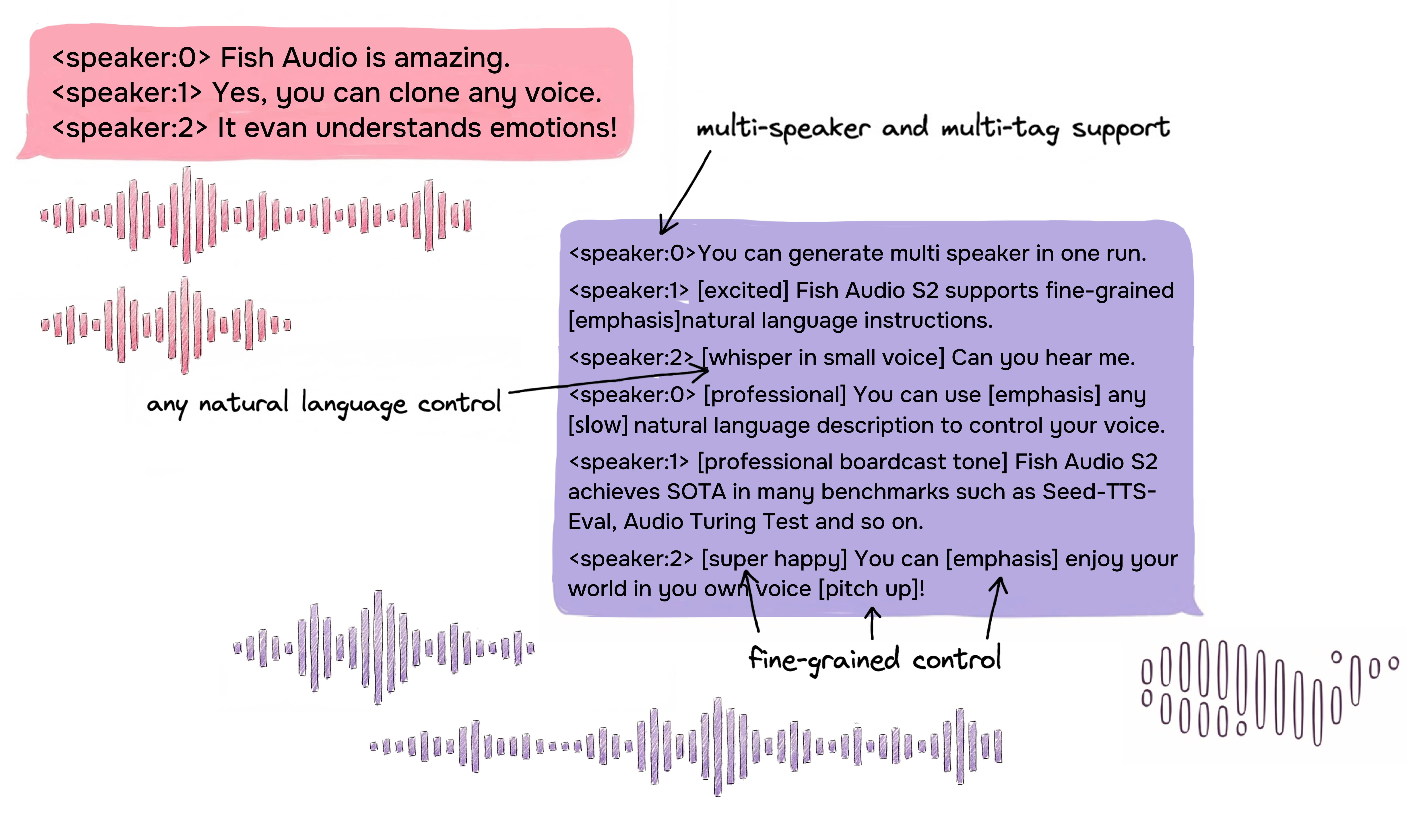
Fish Audio S2는 사용자가 여러 화자가 포함된 참조 오디오를 업로드할 수 있도록 하며, 모델은 <|speaker:i|> 토큰을 통해 각 화자의 특징을 처리합니다. 그런 다음 화자 ID 토큰으로 모델의 성능을 제어하여 한 번의 생성으로 여러 화자를 포함할 수 있습니다. 이전처럼 각 화자마다 별도로 참조 오디오를 업로드하고 음성을 생성할 필요가 없습니다.
멀티 턴 대화 생성
모델 컨텍스트의 확장 덕분에 이제 이전 정보를 활용하여 후속 생성 콘텐츠의 표현력을 높이고 콘텐츠의 자연스러움을 향상시킬 수 있습니다.
빠른 음성 복제
Fish Audio S2는 짧은 참조 샘플(일반적으로 10-30초)을 사용하여 정확한 음성 복제를 지원합니다. 모델은 음색, 말하기 스타일 및 감정적 경향을 캡처하여 추가 미세 조정 없이 사실적이고 일관된 복제 음성을 생성합니다. SGLang 서버 사용은 SGLang-Omni README 를 참고하세요.
크레딧
기술 보고서
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
@misc{liao2026fishaudios2technical,
title={Fish Audio S2 Technical Report},
author={Shijia Liao and Yuxuan Wang and Songting Liu and Yifan Cheng and Ruoyi Zhang and Tianyu Li and Shidong Li and Yisheng Zheng and Xingwei Liu and Qingzheng Wang and Zhizhuo Zhou and Jiahua Liu and Xin Chen and Dawei Han},
year={2026},
eprint={2603.08823},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.08823},
}