

许可声明
此代码库及其相关的模型权重均在 FISH AUDIO RESEARCH LICENSE 下发布。更多详情请参考 LICENSE。
法律免责声明
我们不对代码库的任何非法使用承担责任。请参考您当地关于 DMCA 和其他相关法律的法规。
快速开始
文档入口
这里是 Fish Audio S2 的官方文档,请按照说明轻松入门。
[!IMPORTANT] 如需使用 SGLang Server,请参考 SGLang-Omni README。
LLM Agent 指南
Fish Audio S2
在开源与闭源方案中都处于领先水平的文本转语音系统
Fish Audio S2 是由 Fish Audio 开发的最新模型。S2 在约 50 种语言、超过 1000 万小时音频数据上完成训练,并结合强化学习对齐与双自回归架构,能够生成自然、真实且情感丰富的语音。
S2 支持通过自然语言标签(如 [laugh]、[whispers]、[super happy])对韵律和情绪进行细粒度行内控制,同时原生支持多说话人和多轮生成。
请访问 Fish Audio 网站 体验在线演示,并阅读博客文章和技术报告了解更多细节。
模型变体
| 模型 | 大小 | 可用性 | 描述 |
|---|---|---|---|
| S2-Pro | 4B 参数 | HuggingFace | 功能齐全的旗舰模型,具有最高质量和稳定性 |
有关模型的更多详情,请参见技术报告。
基准测试结果
| 基准 | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER(中文) | 0.54%(总体最佳) |
| Seed-TTS Eval — WER(英文) | 0.99%(总体最佳) |
| Audio Turing Test(含指令) | 0.515 后验均值 |
| EmergentTTS-Eval — 胜率 | 81.88%(总体最高) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — 质量 | 4.51 / 5.0 |
| 多语言(MiniMax Testset)— 最佳 WER | 24 种语言中的 11 种 |
| 多语言(MiniMax Testset)— 最佳 SIM | 24 种语言中的 17 种 |
在 Seed-TTS Eval 上,S2 在所有已评估模型(包括闭源系统)中实现了最低 WER:Qwen3-TTS(0.77/1.24)、MiniMax Speech-02(0.99/1.90)、Seed-TTS(1.12/2.25)。在 Audio Turing Test 上,S2 的 0.515 相比 Seed-TTS(0.417)提升 24%,相比 MiniMax-Speech(0.387)提升 33%。在 EmergentTTS-Eval 中,S2 在副语言学(91.61% 胜率)、疑问句(84.41%)和句法复杂度(83.39%)等维度表现尤为突出。
亮点
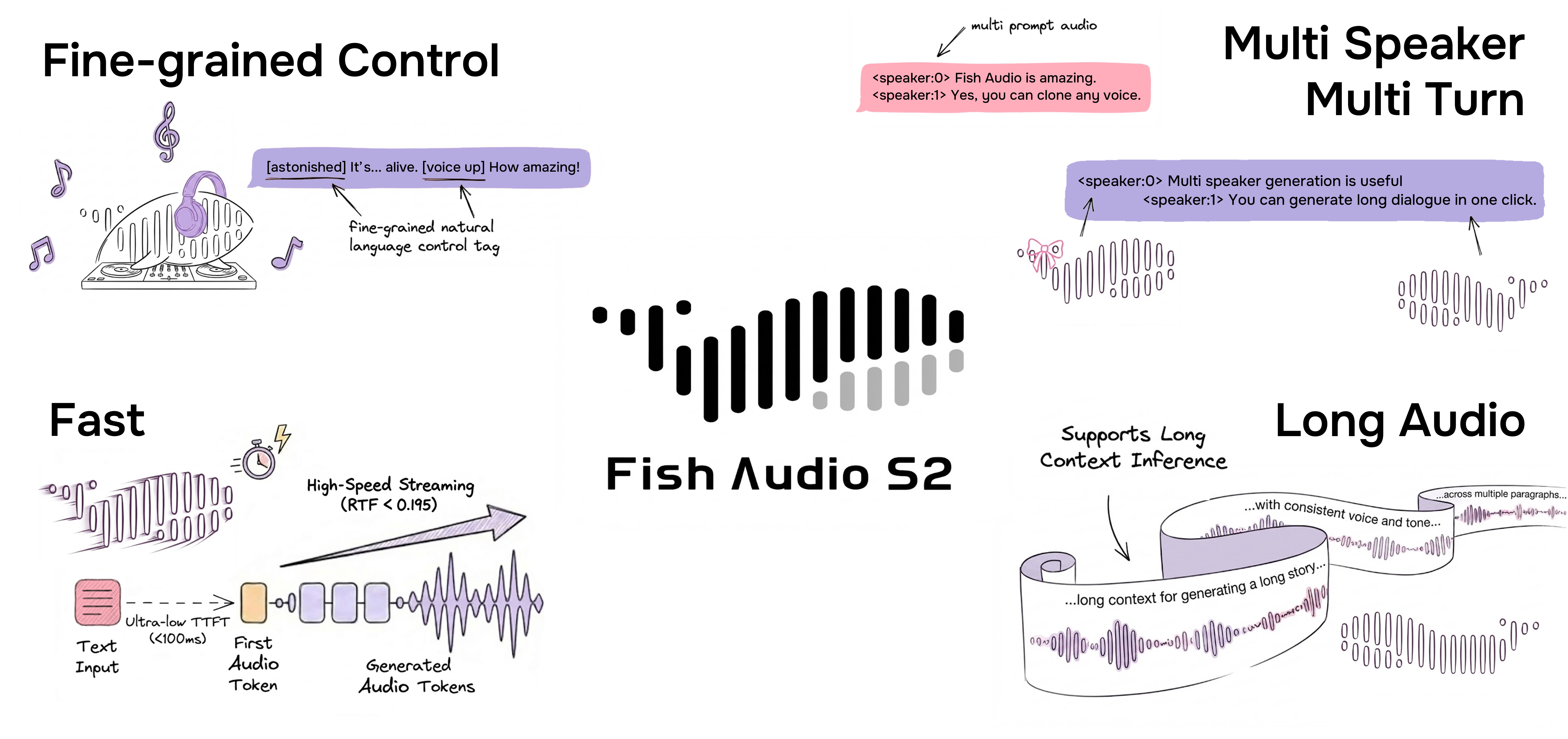
通过自然语言进行细粒度行内控制
Fish Audio S2 支持在文本中的特定词或短语位置直接嵌入自然语言指令,从而对语音生成进行局部控制。与依赖固定预设标签不同,S2 接受自由形式的文本描述,例如 [whisper in small voice]、[professional broadcast tone] 或 [pitch up],实现词级别的开放式表达控制。
双自回归架构(Dual-Autoregressive)
S2 基于仅解码器 Transformer,并结合 RVQ 音频编解码器(10 个码本,约 21 Hz 帧率)。Dual-AR 架构将生成拆分为两个阶段:
- Slow AR 沿时间轴运行,预测主语义码本。
- Fast AR 在每个时间步生成剩余 9 个残差码本,用于重建细粒度声学细节。
这种非对称设计(时间轴 4B 参数、深度轴 400M 参数)在保持音频保真度的同时,提高了推理效率。
强化学习对齐
S2 使用 Group Relative Policy Optimization(GRPO)进行后训练对齐。用于过滤和标注训练数据的同一批模型被直接复用为 RL 的奖励模型,从而避免了预训练数据分布与后训练目标之间的不匹配。奖励信号综合了语义准确性、指令遵循、声学偏好评分与音色相似度。
基于 SGLang 的生产级流式推理
由于 Dual-AR 架构在结构上与标准自回归 LLM 同构,S2 可以直接继承 SGLang 提供的 LLM 原生服务优化能力,包括连续批处理、分页 KV Cache、CUDA Graph Replay 与基于 RadixAttention 的前缀缓存。
在单张 NVIDIA H200 GPU 上:
- 实时因子(RTF): 0.195
- 首音频延迟: 约 100 ms
- 吞吐: 在 RTF 低于 0.5 的情况下达到 3,000+ acoustic tokens/s
多语言支持
Fish Audio S2 支持高质量的多语言文本转语音,无需音素或特定语言的预处理。包括:
英语、中文、日语、韩语、阿拉伯语、德语、法语...
以及更多!
列表正在不断扩大,请查看 Fish Audio 获取最新发布。
原生多说话人生成
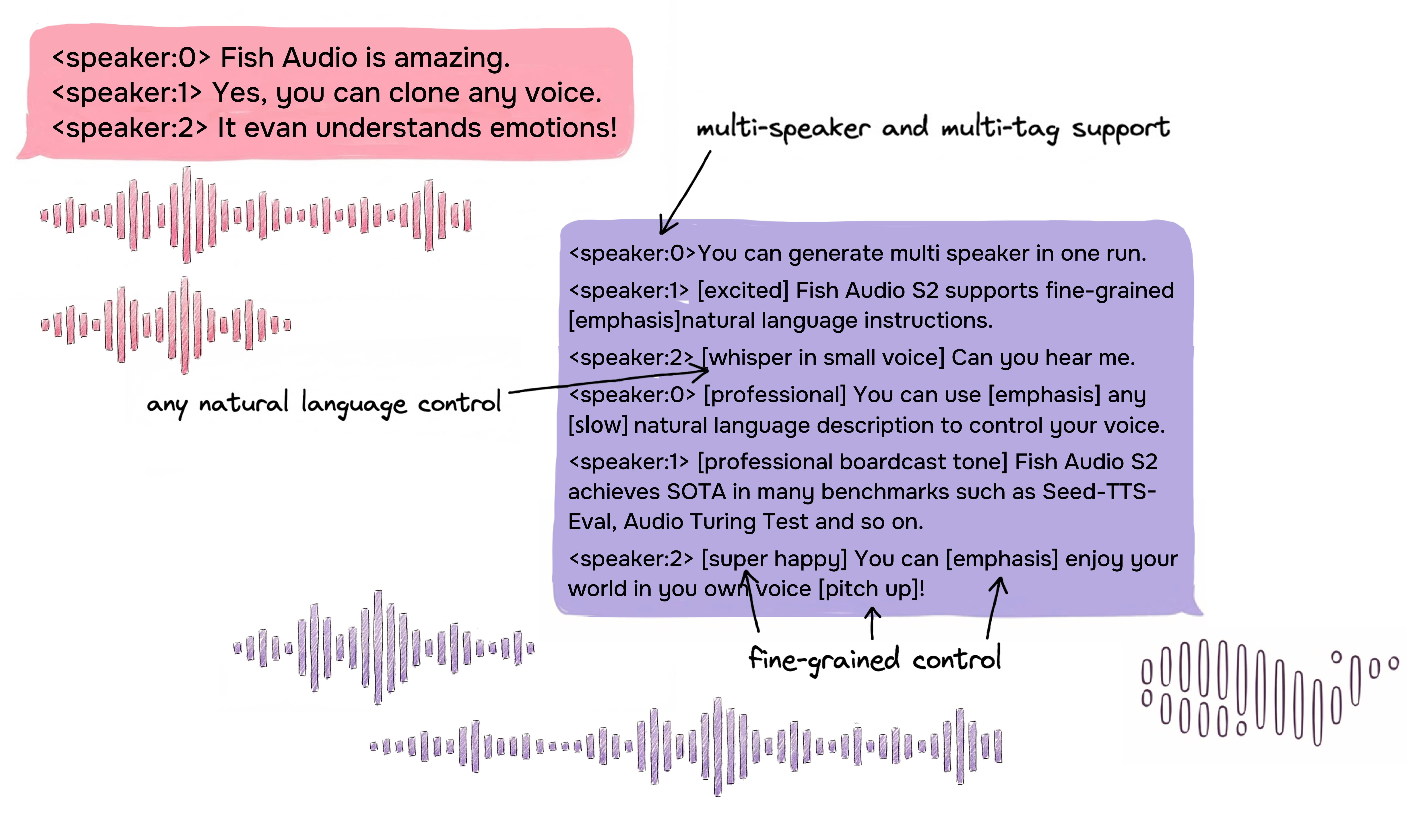
Fish Audio S2 允许用户上传包含多个说话人的参考音频,模型将通过 <|speaker:i|> 令牌处理每个说话人的特征。之后您可以通过说话人 ID 令牌控制模型的表现,从而实现一次生成中包含多个说话人。再也不需要像以前那样针对每个说话人都单独上传参考音频与生成语音了。
多轮对话生成
得益于模型上下文的扩展,我们的模型现在可以借助上文的信息提高后续生成内容的表现力,从而提升内容的自然度。
快速语音克隆
Fish Audio S2 支持使用短参考样本(通常为 10-30 秒)进行准确的语音克隆。模型可以捕捉音色、说话风格和情感倾向,无需额外微调即可生成逼真且一致的克隆语音。 如需使用 SGLang Server,请参考 SGLang-Omni README 。
致谢
技术报告
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
@misc{liao2026fishaudios2technical,
title={Fish Audio S2 Technical Report},
author={Shijia Liao and Yuxuan Wang and Songting Liu and Yifan Cheng and Ruoyi Zhang and Tianyu Li and Shidong Li and Yisheng Zheng and Xingwei Liu and Qingzheng Wang and Zhizhuo Zhou and Jiahua Liu and Xin Chen and Dawei Han},
year={2026},
eprint={2603.08823},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.08823},
}