

تنبيه الترخيص
يتم إصدار قاعدة الأكواد هذه وأوزان النماذج المرتبطة بها بموجب رخصة FISH AUDIO RESEARCH LICENSE. يرجى الرجوع إلى LICENSE لمزيد من التفاصيل.
إخلاء المسؤولية القانونية
نحن لا نتحمل أي مسؤولية عن أي استخدام غير قانوني لقاعدة الأكواد. يرجى مراجعة القوانين المحلية المتعلقة بـ DMCA والقوانين الأخرى ذات الصلة.
البدء السريع
ابدأ من الوثائق
هذه هي الوثائق الرسمية لـ Fish Audio S2، ويمكنك البدء مباشرة عبر الروابط التالية:
[!IMPORTANT] بالنسبة لخادم SGLang، راجع SGLang-Omni README.
دليل وكلاء LLM
Fish Audio S2
أفضل نظام لتحويل النص إلى كلام بين الأنظمة مفتوحة المصدر ومغلقة المصدر
Fish Audio S2 هو أحدث نموذج من Fish Audio. تم تدريبه على أكثر من 10 ملايين ساعة صوتية عبر نحو 50 لغة، ويجمع بين المواءمة بالتعلم المعزز وبنية Dual-Autoregressive لإنتاج كلام طبيعي وواقعي وغني بالتعبير العاطفي.
يدعم S2 التحكم الدقيق في النبرة والعاطفة داخل النص نفسه باستخدام وسوم باللغة الطبيعية مثل [laugh] و[whispers] و[super happy]، كما يدعم بشكل أصيل توليد متحدثين متعددين وحوارات متعددة الأدوار.
يمكنك تجربة النموذج مباشرة عبر موقع Fish Audio، وقراءة المزيد في منشور المدونة والتقرير التقني.
إصدارات النموذج
| النموذج | الحجم | التوفر | الوصف |
|---|---|---|---|
| S2-Pro | 4B معلمة | HuggingFace | نموذج رائد كامل الميزات بأعلى مستوى من الجودة والاستقرار |
يمكن العثور على مزيد من التفاصيل في التقرير التقني.
نتائج القياس المعياري
| المعيار | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (الصينية) | 0.54% (الأفضل إجمالاً) |
| Seed-TTS Eval — WER (الإنجليزية) | 0.99% (الأفضل إجمالاً) |
| Audio Turing Test (مع التعليمات) | 0.515 المتوسط البعدي |
| EmergentTTS-Eval — معدل الفوز | 81.88% (الأعلى إجمالاً) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — الجودة | 4.51 / 5.0 |
| متعدد اللغات (MiniMax Testset) — أفضل WER | 11 من 24 لغة |
| متعدد اللغات (MiniMax Testset) — أفضل SIM | 17 من 24 لغة |
في Seed-TTS Eval، حقق S2 أقل WER بين جميع النماذج التي تم تقييمها، بما في ذلك الأنظمة المغلقة: Qwen3-TTS (0.77/1.24)، وMiniMax Speech-02 (0.99/1.90)، وSeed-TTS (1.12/2.25). وفي Audio Turing Test، تفوقت قيمة 0.515 على Seed-TTS (0.417) بنسبة 24% وعلى MiniMax-Speech (0.387) بنسبة 33%. وفي EmergentTTS-Eval، حقق S2 نتائج قوية بشكل خاص في الخصائص شبه اللغوية (91.61%)، والأسئلة (84.41%)، والتعقيد النحوي (83.39%).
أبرز المميزات
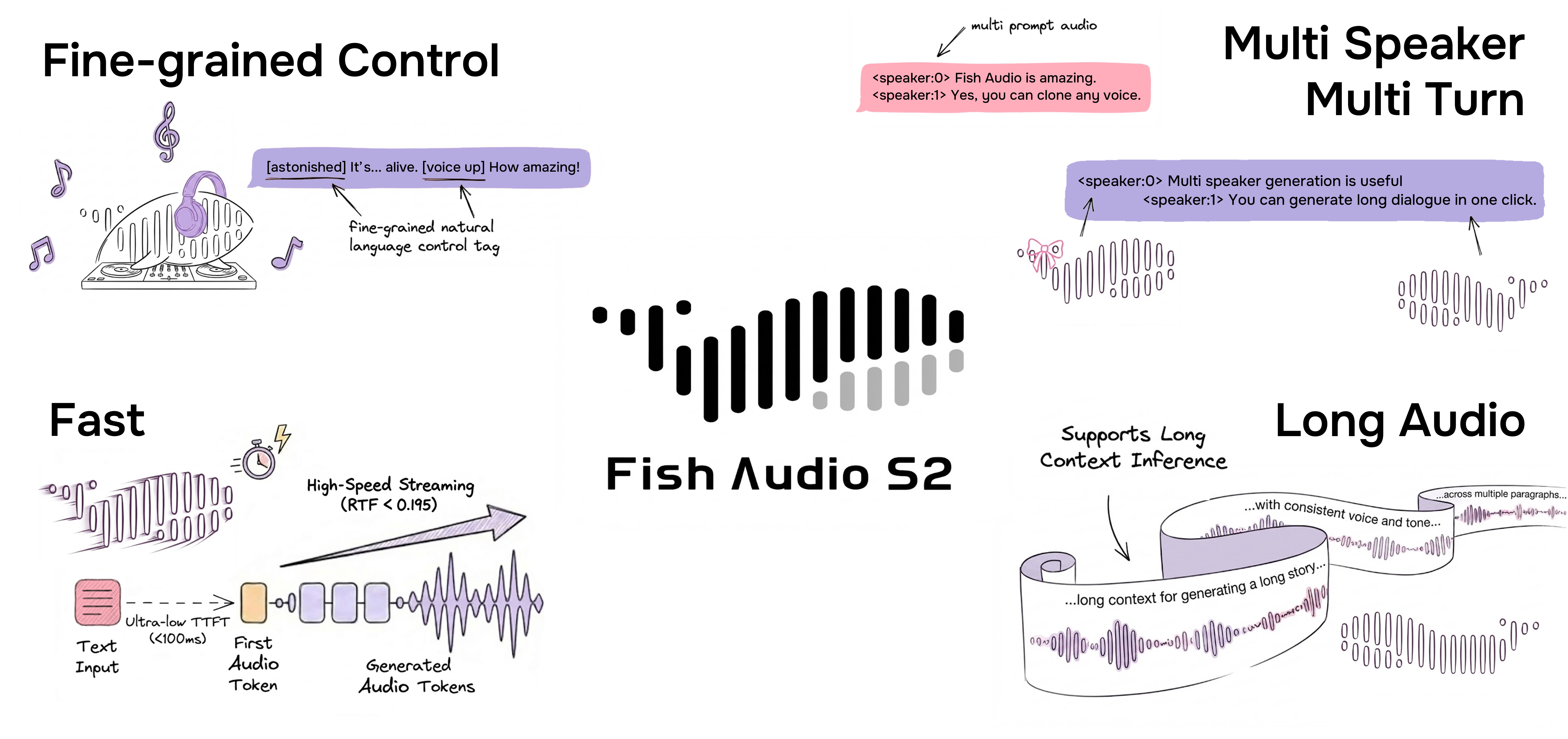
تحكم مضمّن دقيق عبر اللغة الطبيعية
يتيح Fish Audio S2 تحكمًا موضعيًا في توليد الكلام من خلال تضمين تعليمات باللغة الطبيعية مباشرة عند مواقع كلمات أو عبارات محددة داخل النص. وبدلًا من الاعتماد على مجموعة ثابتة من الوسوم المُعرّفة مسبقًا، يقبل S2 أوصافًا نصية حرة مثل [whisper in small voice] أو [professional broadcast tone] أو [pitch up]، مما يتيح تحكمًا مفتوحًا في التعبير على مستوى الكلمة.
بنية Dual-Autoregressive
يعتمد S2 على Transformer أحادي الاتجاه (Decoder-only) مع مُرمّز صوتي قائم على RVQ (عدد 10 codebooks وبمعدل إطارات يقارب 21 هرتز). وتُقسّم بنية Dual-AR عملية التوليد إلى مرحلتين:
- Slow AR يعمل على المحور الزمني ويتنبأ بالـ semantic codebook الأساسي.
- Fast AR يولّد الـ 9 residual codebooks المتبقية في كل خطوة زمنية لإعادة بناء التفاصيل الصوتية الدقيقة.
هذا التصميم غير المتماثل (4B معلمة على المحور الزمني و400M على محور العمق) يرفع كفاءة الاستدلال مع الحفاظ على جودة الصوت.
المواءمة بالتعلم المعزز
يستخدم S2 خوارزمية Group Relative Policy Optimization (GRPO) للمواءمة بعد التدريب. ويتم إعادة استخدام نفس النماذج التي استُخدمت لتصفية بيانات التدريب وتعليقها كنماذج مكافأة في التعلم المعزز مباشرة، مما يلغي عدم تطابق التوزيع بين بيانات ما قبل التدريب وأهداف ما بعد التدريب. وتجمع إشارة المكافأة بين الدقة الدلالية، والالتزام بالتعليمات، وتقييم التفضيل الصوتي، وتشابه النبرة.
البث الإنتاجي عبر SGLang
لأن بنية Dual-AR متماثلة بنيويًا مع نماذج LLM autoregressive القياسية، فإن S2 يرث مباشرة تحسينات الخدمة الأصلية في SGLang، بما في ذلك: continuous batching، وpaged KV cache، وCUDA graph replay، وprefix caching المعتمد على RadixAttention.
على بطاقة NVIDIA H200 واحدة:
- عامل الزمن الحقيقي (RTF): 0.195
- الزمن حتى أول مقطع صوتي: حوالي 100 مللي ثانية
- معدل المعالجة: أكثر من 3,000 acoustic tokens/s مع الحفاظ على RTF أقل من 0.5
دعم لغات متعددة
يدعم Fish Audio S2 تحويل النص إلى كلام بجودة عالية ولغات متعددة دون الحاجة إلى رموز صوتية أو معالجة مسبقة خاصة بكل لغة. بما في ذلك:
الإنجليزية، الصينية، اليابانية، الكورية، العربية، الألمانية، الفرنسية...
وأكثر من ذلك بكثير!
القائمة في توسع مستمر، تحقق من Fish Audio لمعرفة أحدث الإصدارات.
توليد أصلي لمتحدثين متعددين
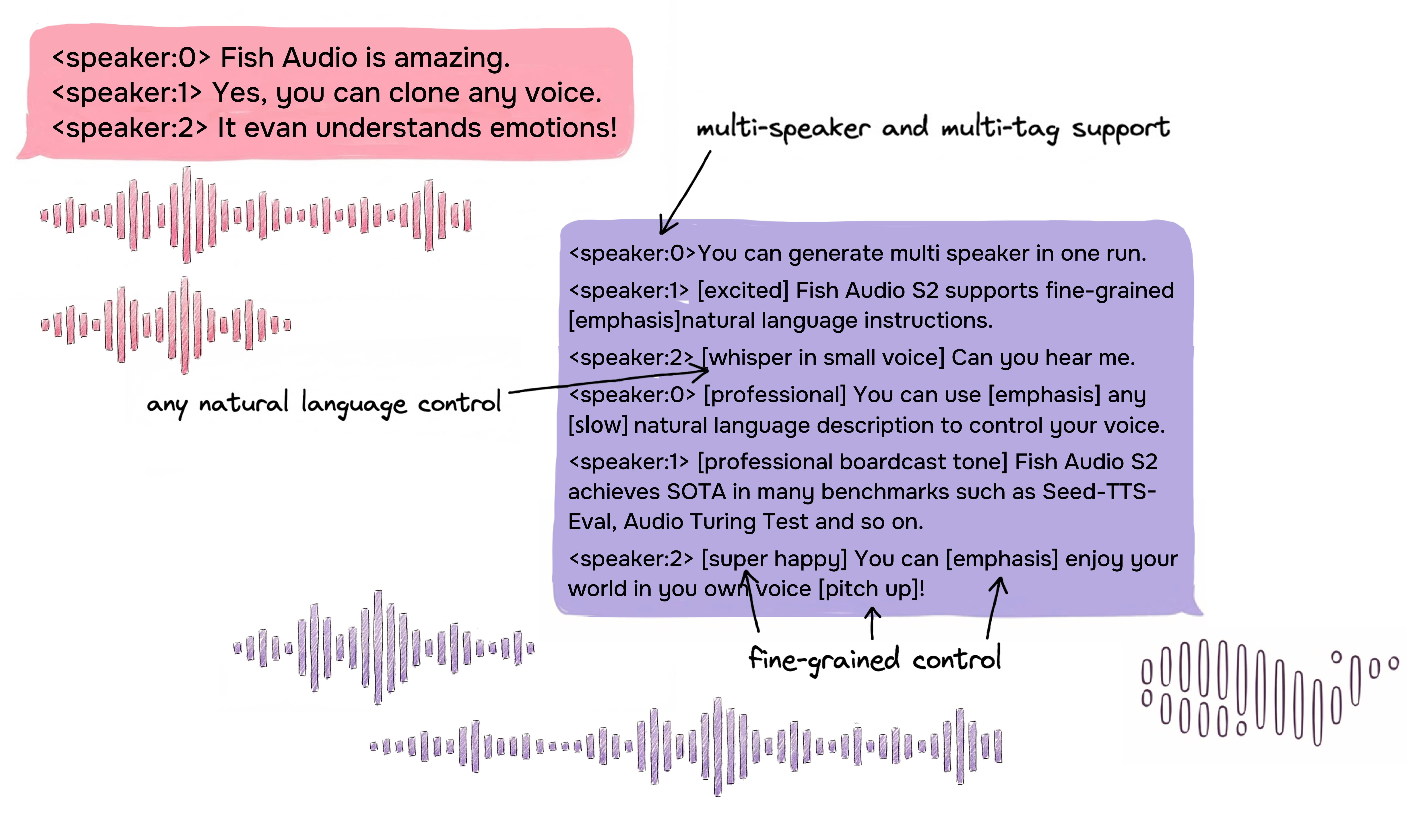
يسمح Fish Audio S2 للمستخدمين برفع صوت مرجعي يحتوي على متحدثين متعددين، وسيتعامل النموذج مع ميزات كل متحدث عبر رمز <|speaker:i|>. يمكنك بعد ذلك التحكم في أداء النموذج باستخدام رمز معرف المتحدث، مما يسمح بتوليد واحد يتضمن متحدثين متعددين. لم تعد بحاجة لرفع ملفات مرجعية منفصلة لكل متحدث.
توليد حوارات متعددة الأدوار
بفضل توسيع سياق النموذج، يمكن لنموذجنا الآن استخدام المعلومات السابقة لتحسين التعبير في المحتوى المولد لاحقاً، مما يزيد من طبيعية المحتوى.
استنساخ صوت سريع
يدعم Fish Audio S2 استنساخ الصوت بدقة باستخدام عينة مرجعية قصيرة (عادةً 10-30 ثانية). يلتقط النموذج نبرة الصوت، وأسلوب التحدث، والميول العاطفية، مما ينتج أصواتاً مستنسخة واقعية ومتسقة دون الحاجة إلى ضبط دقيق إضافي. لاستخدام خادم SGLang، راجع SGLang-Omni README .
شكر وتقدير
التقرير التقني
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
@misc{liao2026fishaudios2technical,
title={Fish Audio S2 Technical Report},
author={Shijia Liao and Yuxuan Wang and Songting Liu and Yifan Cheng and Ruoyi Zhang and Tianyu Li and Shidong Li and Yisheng Zheng and Xingwei Liu and Qingzheng Wang and Zhizhuo Zhou and Jiahua Liu and Xin Chen and Dawei Han},
year={2026},
eprint={2603.08823},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.08823},
}